
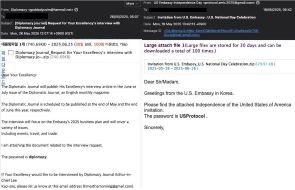
.jpg)




















.gif)
이미지·언어 동시 이해하는 Vision Language Model(VLM) …AI 발전 새 경계 열어
생성형 AI 멀티모달 데이터부터 경량화 모델까지 집중 논의
[보안뉴스 여이레 기자] 오지큐 기술연구소(GYN)가 주최하고 한국영상정보연구조합이 주관하는 ‘Vision Language Model (VLM) 콘퍼런스’가 27일 서울 강남구 코엑스에서 열린다.

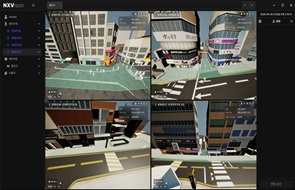
인공지능(AI) 분야에서 이미지와 언어를 동시에 이해하고 생성하는 Vision Language Model에 대한 관심이 빠르게 커지고 있다.
컴퓨터 비전과 자연어처리 기술의 융합을 통해 인간과 더욱 유사한 인지 능력을 구현하는 VLM은 다양한 산업에 혁신을 가져오면서 AI 발전의 새로운 경계를 열고 있다는 평가다.
이번 행사는 VLM 기술 교류를 목적으로 개최되며, 영상보안과 물리보안 관련 산학연 관계자라면 누구나 참석이 능하다.
콘퍼런스는 주최측 오지큐 기술연구소 방승온 연구소장의 ‘AI가 상황을 이해하는 시대 - 영상과 언어를 연결한 어시스턴트 Assistant AI 보안관제’ 강연으로 시작한다.
이어 김동칠 한국전자기술연구원 책임이 ‘생성형 AI 기반 멀티모달 데이터를 활용한 지능형 보안관제’에 대해 강연한다.
마지막으로 김경수 서울대학교 첨단융합학부 부교수가 ‘VLM기반 지능형 영상보안 관제기술-영상 기반 언어 생성 최신 경량화 모델’에 대한 인사이트를 공유한다.
강연 후에는 별도의 질의응답 시간도 마련돼 참석자는 자유롭게 강연자들과 소통할 수 있다.
[여이레 기자(gore@boannews.com)]
생성형 AI 멀티모달 데이터부터 경량화 모델까지 집중 논의
[보안뉴스 여이레 기자] 오지큐 기술연구소(GYN)가 주최하고 한국영상정보연구조합이 주관하는 ‘Vision Language Model (VLM) 콘퍼런스’가 27일 서울 강남구 코엑스에서 열린다.
인공지능(AI) 분야에서 이미지와 언어를 동시에 이해하고 생성하는 Vision Language Model에 대한 관심이 빠르게 커지고 있다.
컴퓨터 비전과 자연어처리 기술의 융합을 통해 인간과 더욱 유사한 인지 능력을 구현하는 VLM은 다양한 산업에 혁신을 가져오면서 AI 발전의 새로운 경계를 열고 있다는 평가다.
이번 행사는 VLM 기술 교류를 목적으로 개최되며, 영상보안과 물리보안 관련 산학연 관계자라면 누구나 참석이 능하다.
콘퍼런스는 주최측 오지큐 기술연구소 방승온 연구소장의 ‘AI가 상황을 이해하는 시대 - 영상과 언어를 연결한 어시스턴트 Assistant AI 보안관제’ 강연으로 시작한다.
이어 김동칠 한국전자기술연구원 책임이 ‘생성형 AI 기반 멀티모달 데이터를 활용한 지능형 보안관제’에 대해 강연한다.
마지막으로 김경수 서울대학교 첨단융합학부 부교수가 ‘VLM기반 지능형 영상보안 관제기술-영상 기반 언어 생성 최신 경량화 모델’에 대한 인사이트를 공유한다.
강연 후에는 별도의 질의응답 시간도 마련돼 참석자는 자유롭게 강연자들과 소통할 수 있다.
[여이레 기자(gore@boannews.com)]
<저작권자: 보안뉴스(www.boannews.com) 무단전재-재배포금지>







.jpg)






.jpg)