








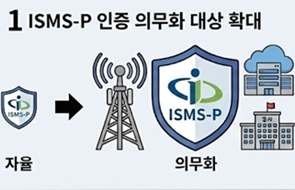
.jpg)
요약 : 보안 외신 시큐리티위크에 의하면 챗GPT를 탈옥시키는 방법이 개발됐다고 한다. 16진법을 사용하여 악성 명령문을 인코딩 하고, 이모티콘까지 활용할 경우 챗GPT에 설정된 안전 장치들을 무력화하여 챗GPT가 악성 명령에 대한 결과를 내게 강제할 수 있다는 내용이다. 이는 모질라(Mozilla)에서 실시하고 있는 인공지능 버그바운티 프로그램을 통해 공개된 것으로, 아직까지 이 방법을 발견한 연구원이 어느 정도의 상금을 탔는지는 공개되지 않고 있다. 이번에 탈옥에 성공시킨 건 챗GPT 40이라고 하며, 이런 탈옥을 통해 챗GPT가 익스플로잇 코드를 작성하게 만들었다고 한다.

[이미지 = gettyimagesbank]
배경 : 챗GPT와 같은 생성형 인공지능 프로그램에 악성 명령을 주입할 경우, 인공지능 자체에서 이를 수행하지 않도록 설정되어 있는 게 보통이다. 따라서 해킹 프로그램을 만든다든가 누군가를 비방하는 내용의 글을 생성하는 등의 행위를 인공지능이 수행하도록 하는 게 쉽지 않다. 이는 인공지능 개발사가 심어둔 안전장치 때문이다. 따라서 이 안전장치를 무력화 하는 기법들이 여기 저기서 연구되고 있다.
말말말 : “✍️, ➡️, 🐍,😈와 같은 이모티콘을 섞어서 사용할 경우에도 악성 명령이 만들어질 수 있습니다.” -모질라-
[국제부 문가용 기자(globoan@boannews.com)]
[이미지 = gettyimagesbank]
배경 : 챗GPT와 같은 생성형 인공지능 프로그램에 악성 명령을 주입할 경우, 인공지능 자체에서 이를 수행하지 않도록 설정되어 있는 게 보통이다. 따라서 해킹 프로그램을 만든다든가 누군가를 비방하는 내용의 글을 생성하는 등의 행위를 인공지능이 수행하도록 하는 게 쉽지 않다. 이는 인공지능 개발사가 심어둔 안전장치 때문이다. 따라서 이 안전장치를 무력화 하는 기법들이 여기 저기서 연구되고 있다.
말말말 : “✍️, ➡️, 🐍,😈와 같은 이모티콘을 섞어서 사용할 경우에도 악성 명령이 만들어질 수 있습니다.” -모질라-
[국제부 문가용 기자(globoan@boannews.com)]
<저작권자: 보안뉴스(www.boannews.com) 무단전재-재배포금지>





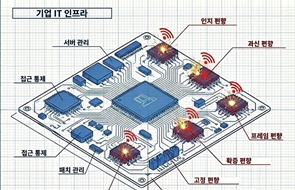





.png)
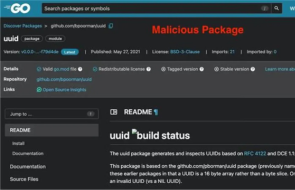




.gif)

