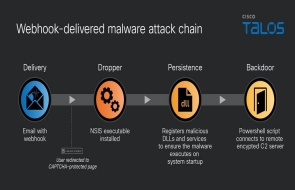
.gif)
서울대·KETI 등 참여... 영상보안 분야 VLM 활용 가능성 논의
[보안뉴스 강초희 기자] 영상언어모델(VLM: Vision Language Model)과 생성형 AI 기술 동향을 공유하는 ‘영상언어모델(VLM) 기술 콘퍼런스’가 오는 3월 19일 일산 킨텍스에서 열린다.

▲영상언어모델(VLM) 기술 콘퍼런스 개최 [출처: 오지큐 기술연구소]
오지큐 기술연구소(GYN)가 주최하고 한국영상정보연구조합이 주관하는 이번 콘퍼런스는 SECON & eGISEC 2026 기간 중 동시 개최 행사로, 킨텍스 제1전시장 2층 콘퍼런스룸 213호에서 진행된다.
이번 행사는 영상언어모델(VLM)과 생성형 AI 분야의 기술 교류를 목적으로 마련됐으며, 영상보안·물리보안 분야 산·학·연·관 관계자 관계자를 대상으로 진행된다.

▲영상언어모델(VLM) 기술 콘퍼런스 프로그램 안내 [출처: 오지큐 기술연구소]
첫 번째 발표에서는 방승온 오지큐 기술연구소 연구소장이 ‘VLM 시대의 지식표현: 온톨로지 기반 해석과 의사결정’을 주제로 영상 데이터 해석과 지식 구조화 기술을 소개한다. 이어 김경수 서울대학교 첨단융합학부 교수가 ‘첨단 VLM 기반 생성형 인공지능 기술 최신 동향’을 발표한다. 또한 김동칠 한국전자기술연구원(KETI) 책임연구원이 ‘생성형 AI 기반 멀티모달 데이터 활용 관제’를 주제로 강단에 선다.
이번 콘퍼런스는 SECON & eGISEC 2026 참관객 누구나 참석할 수 있는 공개 행사로 진행된다.
한편 물리보안과 사이버보안을 아우르는 국내 최대 통합보안 전시회인 제25회 세계보안엑스포와 제14회 전자정부 정보보호 솔루션 페어(SECON & eGISEC 2026)가 3월 18일부터 20일까지 일산 킨텍스 제1전시장(콘퍼런스룸 2F, 그랜드볼룸 3F)에서 열린다. SECON & eGISEC 2026은 공식 홈페이지를 통해 등록하면 무료로 참관할 수 있다.
[강초희 기자(sw@boannews.com)]
[보안뉴스 강초희 기자] 영상언어모델(VLM: Vision Language Model)과 생성형 AI 기술 동향을 공유하는 ‘영상언어모델(VLM) 기술 콘퍼런스’가 오는 3월 19일 일산 킨텍스에서 열린다.
▲영상언어모델(VLM) 기술 콘퍼런스 개최 [출처: 오지큐 기술연구소]
오지큐 기술연구소(GYN)가 주최하고 한국영상정보연구조합이 주관하는 이번 콘퍼런스는 SECON & eGISEC 2026 기간 중 동시 개최 행사로, 킨텍스 제1전시장 2층 콘퍼런스룸 213호에서 진행된다.
이번 행사는 영상언어모델(VLM)과 생성형 AI 분야의 기술 교류를 목적으로 마련됐으며, 영상보안·물리보안 분야 산·학·연·관 관계자 관계자를 대상으로 진행된다.
▲영상언어모델(VLM) 기술 콘퍼런스 프로그램 안내 [출처: 오지큐 기술연구소]
첫 번째 발표에서는 방승온 오지큐 기술연구소 연구소장이 ‘VLM 시대의 지식표현: 온톨로지 기반 해석과 의사결정’을 주제로 영상 데이터 해석과 지식 구조화 기술을 소개한다. 이어 김경수 서울대학교 첨단융합학부 교수가 ‘첨단 VLM 기반 생성형 인공지능 기술 최신 동향’을 발표한다. 또한 김동칠 한국전자기술연구원(KETI) 책임연구원이 ‘생성형 AI 기반 멀티모달 데이터 활용 관제’를 주제로 강단에 선다.
이번 콘퍼런스는 SECON & eGISEC 2026 참관객 누구나 참석할 수 있는 공개 행사로 진행된다.
한편 물리보안과 사이버보안을 아우르는 국내 최대 통합보안 전시회인 제25회 세계보안엑스포와 제14회 전자정부 정보보호 솔루션 페어(SECON & eGISEC 2026)가 3월 18일부터 20일까지 일산 킨텍스 제1전시장(콘퍼런스룸 2F, 그랜드볼룸 3F)에서 열린다. SECON & eGISEC 2026은 공식 홈페이지를 통해 등록하면 무료로 참관할 수 있다.
[강초희 기자(sw@boannews.com)]
<저작권자: 보안뉴스(www.boannews.com) 무단전재-재배포금지>






.jpg)

.jpg)





.jpg)

.jpg)