








.gif)
박찬영 교수팀, 합성 데이터 활용해 전문성과 범용성 확보한 AI 개발
소셜·의료·금융 등 민감 데이터 다루는 기관 간 협업 AI 모델 개발에 새로운 가능성 제시
[보안뉴스 조재호 기자] 카이스트(총장 이광형)는 박찬영 산업및시스템공학과 교수 연구팀이 연합학습의 성능 저하 문제를 해결하고, 인공지능(AI) 모델의 일반화 성능을 크게 향상한 새로운 학습 방법을 개발했다고 15일 밝혔다.
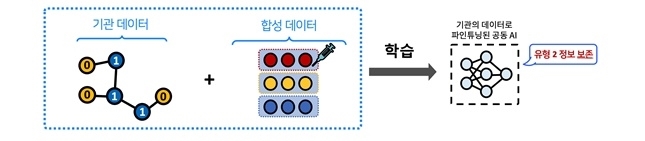
▲합성데이터를 활용한 AI 모델 학습 모식도 [자료: 카이스트]
연합학습은 여러 기관이 데이터를 직접 주고받지 않고도 공동으로 AI를 학습시킬 수 있는 방식이다. 다만, 이 방식을 활용한 공동 AI 모델은 각 기관이 최적화하는 과정에서 문제가 발생한다. 기존 지식이 희석되면서 특정 기관의 데이터 특성에만 과도하게 적응하는 ‘지역 과적합’ 문제가 발생할 수 있다.
예를 들어 여러 은행이 공동 대출 심사 AI를 구축했는데, 특정 은행이 대기업 고객 데이터를 중심으로 최적화하면 AI는 대기업 심사에 강점을 보이지만 개인이나 스타트업 고객 심사에서는 성능이 떨어진다.
박 교수 연구팀은 이를 해결하기 위해 ‘합성 데이터’ 방식을 도입했다. 각 기관의 데이터에서 핵심적이고 대표적인 특징만 추출해 개인정보를 포함하지 않은 가상 데이터를 생겅하고, 이를 최적화하는 과정에 적용하는 것이다. 이를 통해 각 기관의 AI는 개인정보 공유 없이 각자의 데이터에 맞춰 전문성을 강화하면서도 공동 학습으로 획득한 일반화 성능을 유지할 수 있게 됐다.
이 방식은 의료·금융 등 데이터 보안이 중요한 분야에서 효과적이며, 소셜미디어나 전자상거래처럼 새로운 사용자와 상품이 지속적으로 추가되는 환경에서도 안정적인 성능을 발휘했다. 새로운 기관이 참여하거나 데이터 특성이 급격히 변하더라도 AI가 안정적으로 성능을 유지할 수 있음을 보여줬다.

▲박찬영 카이스트 산업및시스템공학과 교수(상단 우측 첫 번째) 연구팀 [자료: 카이스트]
박찬영 산업및시스템공학과 교수는 “이번 연구는 데이터 프라이버시를 지키면서도 각 기관의 AI가 전문성과 범용성을 동시에 보장할 수 있는 새로운 길을 열었다”라며 “의료 AI나 금융 사기 탐지 AI처럼 데이터 협업이 필수적이지만 보안이 중요한 분야에서 큰 도움이 될 것”이라고 말했다.
이번 연구는 지난 4월 싱가포르에서 열린 인공지능 분야 학술대회인 ‘국제표현학습학회 2025’(ICLR)에서 상위 1.8%의 우수 논문에만 선정되는 구두 발표 대상으로 채택되면서 그 우수성을 입증받았다.
[조재호 기자(sw@boannews.com)]
소셜·의료·금융 등 민감 데이터 다루는 기관 간 협업 AI 모델 개발에 새로운 가능성 제시
[보안뉴스 조재호 기자] 카이스트(총장 이광형)는 박찬영 산업및시스템공학과 교수 연구팀이 연합학습의 성능 저하 문제를 해결하고, 인공지능(AI) 모델의 일반화 성능을 크게 향상한 새로운 학습 방법을 개발했다고 15일 밝혔다.
▲합성데이터를 활용한 AI 모델 학습 모식도 [자료: 카이스트]
연합학습은 여러 기관이 데이터를 직접 주고받지 않고도 공동으로 AI를 학습시킬 수 있는 방식이다. 다만, 이 방식을 활용한 공동 AI 모델은 각 기관이 최적화하는 과정에서 문제가 발생한다. 기존 지식이 희석되면서 특정 기관의 데이터 특성에만 과도하게 적응하는 ‘지역 과적합’ 문제가 발생할 수 있다.
예를 들어 여러 은행이 공동 대출 심사 AI를 구축했는데, 특정 은행이 대기업 고객 데이터를 중심으로 최적화하면 AI는 대기업 심사에 강점을 보이지만 개인이나 스타트업 고객 심사에서는 성능이 떨어진다.
박 교수 연구팀은 이를 해결하기 위해 ‘합성 데이터’ 방식을 도입했다. 각 기관의 데이터에서 핵심적이고 대표적인 특징만 추출해 개인정보를 포함하지 않은 가상 데이터를 생겅하고, 이를 최적화하는 과정에 적용하는 것이다. 이를 통해 각 기관의 AI는 개인정보 공유 없이 각자의 데이터에 맞춰 전문성을 강화하면서도 공동 학습으로 획득한 일반화 성능을 유지할 수 있게 됐다.
이 방식은 의료·금융 등 데이터 보안이 중요한 분야에서 효과적이며, 소셜미디어나 전자상거래처럼 새로운 사용자와 상품이 지속적으로 추가되는 환경에서도 안정적인 성능을 발휘했다. 새로운 기관이 참여하거나 데이터 특성이 급격히 변하더라도 AI가 안정적으로 성능을 유지할 수 있음을 보여줬다.
▲박찬영 카이스트 산업및시스템공학과 교수(상단 우측 첫 번째) 연구팀 [자료: 카이스트]
박찬영 산업및시스템공학과 교수는 “이번 연구는 데이터 프라이버시를 지키면서도 각 기관의 AI가 전문성과 범용성을 동시에 보장할 수 있는 새로운 길을 열었다”라며 “의료 AI나 금융 사기 탐지 AI처럼 데이터 협업이 필수적이지만 보안이 중요한 분야에서 큰 도움이 될 것”이라고 말했다.
이번 연구는 지난 4월 싱가포르에서 열린 인공지능 분야 학술대회인 ‘국제표현학습학회 2025’(ICLR)에서 상위 1.8%의 우수 논문에만 선정되는 구두 발표 대상으로 채택되면서 그 우수성을 입증받았다.
[조재호 기자(sw@boannews.com)]
<저작권자: 보안뉴스(www.boannews.com) 무단전재-재배포금지>











.jpg)








.jpg)